联系电话:18520175978(微信同号)

在我们的日常生活中,声音无处不在。
从清晨的鸟鸣到夜晚的虫叫,从朋友的问候到陌生人的搭讪,声音是我们与世界沟通的重要方式。
声音也可以成为识别一个人的独特标识,这是什么原理呢?今天就来科普一下“声纹识别”。

一、人类声纹的独特性
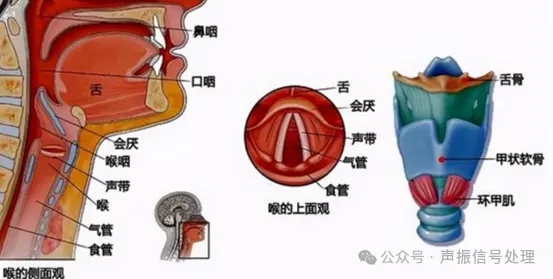
声纹是声波的频谱特征图谱,就像指纹、虹膜一样,由先天生理结构与后天发声习惯共同塑造:
声带的厚度、长度决定了基础音高,
咽喉、鼻腔的共鸣腔形状影响音色,
甚至呼吸节奏、说话时的肌肉紧张度,都会在声音中留下独特印记。
这些特征组合形成的声纹,让每个人的声音都具备稳定性和唯一性,这正是声纹识别技术的核心前提。
图片来源于网络
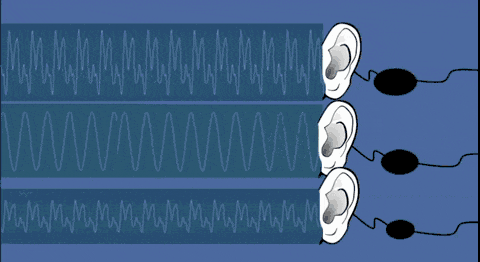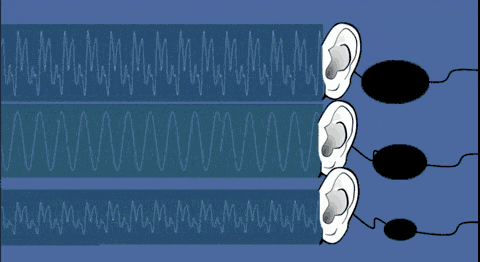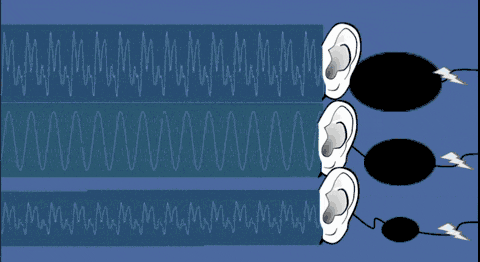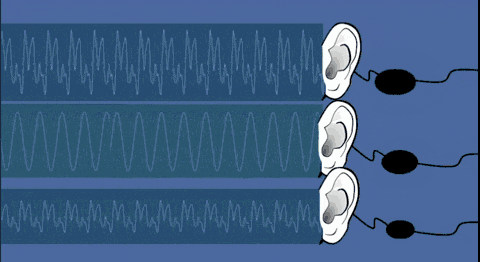
不同声音的特殊性,除了发声源的唯一性以外,还有人们听觉感知的差异。
听觉系统(耳、脑、骨传导)对不同频率声音的感知存在个体差异(比如有人对高频更敏感、有人对低频更敏锐)。
再结合大脑对语音特征的主观解码偏好,进一步强化了同一声音在不同人耳中呈现的声纹感知差异,最终让声音成为兼具生理唯一性与感知独特性的身份标识。
那么,机器如何通过声音识别身份呢?
图片来源于网络
二、机器声纹识别
首先通过麦克风采集语音信号,但原始声音会夹杂环境噪音、生理干扰以及无效间隙,这些杂质会严重干扰后续特征提取的准确性。
因此,第一步必须进行多维度预处理,通过针对性技术剔除干扰,让声纹显出原形。
常用预处理方法有四种。
1、噪声抑制
核心方法包括自适应噪声抵消(Adaptive Noise Cancellation,ANC)和谱减法。
ANC通过双麦克风采集:
一个采集语音+噪声,
一个专门采集环境噪声,
利用算法实时生成“反向声波”抵消杂音;
谱减法则先分析信号频谱,识别出噪声的频率分布,再从原始信号中减去噪声频谱。
通过噪声抑制,可将信噪比(SNR)提升,能让语音清晰度提升80%以上,避免噪声“掩盖”真实声纹特征。

2、预加重
人类发声时,声带振动的谐波、清辅音的湍流摩擦声会形成与声道生理结构和发音习惯密切相关的高频成分,这类成分虽因空气吸收、设备限制等发生显著自然衰减,却是声纹识别的关键。
空气传播声音随距离和频率的衰减曲线如下图所示:
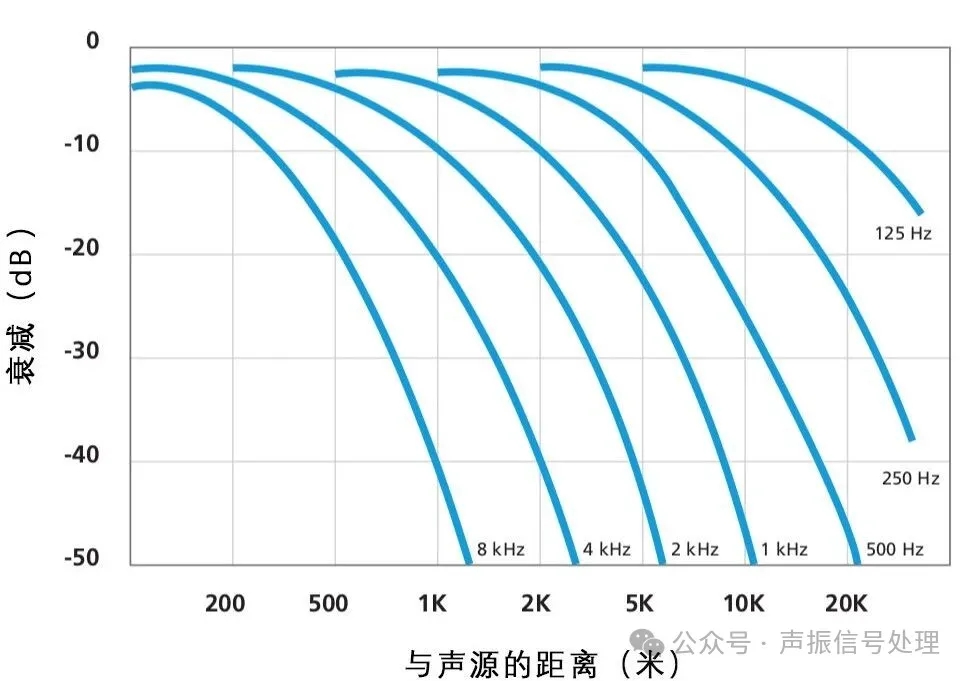
图片来源于 Brüel & Kjær 2001
相对于区分度低的低频语义相关成分,高频段的共振峰偏移、频谱纹理等细节具有极强个体特异性,其衰减会直接降低声纹特征维度与识别精度。
在预处理中,可以通过高通滤波器放大高频信号,补偿频谱衰减。
通过预加重,可以让声纹的高频辨识度提升。
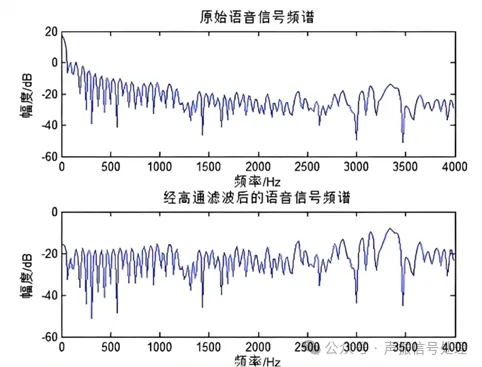
图片来源于网络
3、端点检测
可以采用短时能量与过零率双阈值法:
短时能量判断信号“有没有声音”(语音段能量远高于静音段),
过零率(Zero Crossing Rate, ZCR)判断“是不是语音”(噪声的过零率通常更杂乱)。
过零率与时域信号对比示意图如下所示:
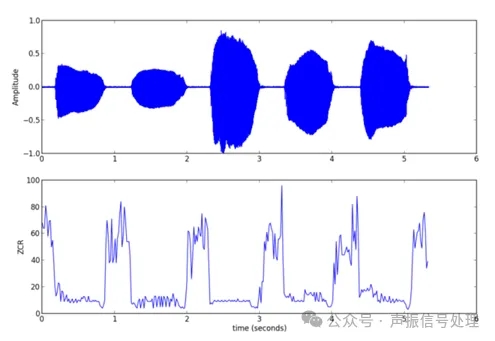
图片来源于网络
通过设定上下阈值,自动裁剪掉开头的呼吸声、中间的长停顿、结尾的尾音拖曳。
通过该处理,可以将无效信号压缩,只保留核心发声段,减少后续处理的算力消耗。
4、归一化
不同人说话音量不同,并且与麦克风距离有差异,会导致信号幅值波动。
通过均值归一化或者峰值归一化,将所有语音信号的幅值统一映射到[-1,1]区间,同时消除直流偏移,让轻声和大声的同一人声纹特征保持一致,避免因音量差异导致的识别误判。
经过这一系列预处理,原始语音信号会从夹杂杂音的模糊音频,变成纯净、规整、细节突出的核心声纹信号,为后续特征提取打下坚实基础。
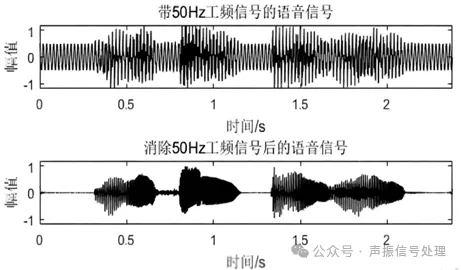
图片来源于网络
三、特征提取
声纹识别技术的关键在于特征提取,即从采集到的语音信号中提取出对说话人具有强区分性和高稳定性的声学或语言特征。
这些特征不仅包括与发音器官解剖学结构直接相关的声学物理特性,还涵盖了受个人习惯、情绪状态、社会环境等因素影响的特征。
声纹特征可以分为三类。
1、基础特征
基础特征直接关联人体发声器官的物理结构,是声纹最稳定的“先天标识”。
基音频率(Pitch,常记为F0):即声带振动的基础频率,决定声音的高低。
男性声带厚长,基音频率通常在80-200Hz;
女性声带薄短,频率多在200-450Hz。
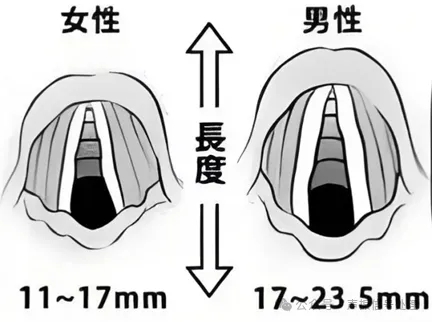
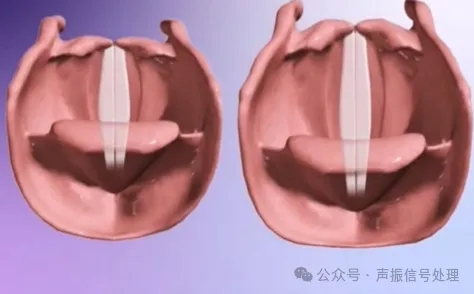
图片来源于网络
即便同性别,声带弹性、紧张度的差异也会让基音呈现独特分布,比如有人说话时基音稳定在120Hz,有人则在110-130Hz间轻微波动。可以通过线性预测编码法(Linear Predictive Coding,LPC)进行预测。
LPC是一种通过过去采样值线性组合预测当前语音信号的参数化分析技术,核心是求解最优预测系数以提取声道特征;
LPC法估计基音频率的核心思路是:先通过LPC分析对语音信号进行逆滤波,得到预测残差信号,再从残差信号中提取周期性特征,进而估计基音频率。该方法可有效抑制声道共振干扰,提升基音检测的准确性。
Pitch,即基音频率,是浊音由声带周期性振动产生的核心特征,是基音周期的倒数,反映语音音调高低。
通过LPC法提取基音频率结果如下图所示:
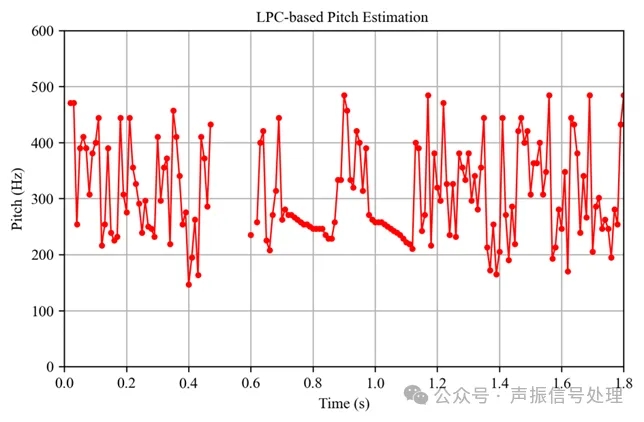
与之对应的时域波形如下图所示:
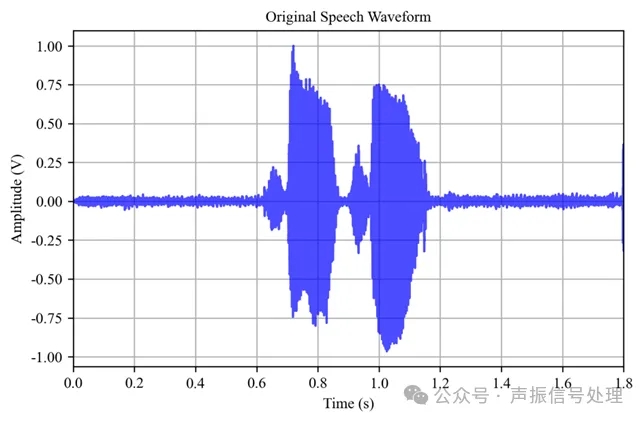
频谱包络:
指声音频谱的整体轮廓,由咽喉、口腔、鼻腔等共鸣腔的形状决定,是音色的核心载体。
就像不同乐器演奏同一音符时音色迥异,人类发声时,共鸣腔的开合状态会过滤不同频率的声波,形成独特的频谱峰值分布,即共振峰。
比如有人音色浑厚,就会导致低频共振峰突出,有人音色清亮,则高频共振峰明显。
这些基础特征能够快速区分性别、年龄等大类差异,为后续精准识别缩小范围,是声纹识别的入门。
2、高阶特征
梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)是声纹识别中最经典、最有效的核心特征,核心优势是模拟人耳听觉特性,精准捕捉细微差异,被誉为人工设计特征的巅峰。
人类听觉系统对不同频率声音的感知响度特性(等响度曲线)如下图所示:
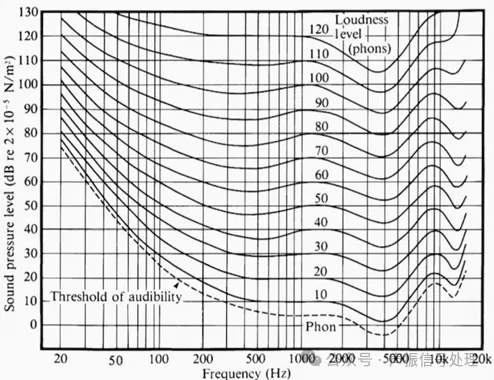
图片来源于网络
MFCC提取流程如下:
(1)分帧加窗:
语音信号是时变非平稳信号,但短时间内(20-30ms)可近似为平稳信号,因此先进行分帧处理:
如将预处理后的连续语音信号,按帧长N=25ms、帧移M=10ms分割。
同时,为避免帧边缘信号的突变失真,给每帧信号加窗,比如:汉明窗(Hamming Window),窗函数公式为:
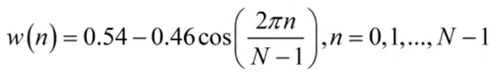
帧边缘的采样点被加权衰减,中间部分保持相对稳定,有效减少频谱泄漏。
(2)频域转换:
分帧后的信号仍处于时域,无法直接体现频率分布,需通过傅里叶变换转化为频域。
对每帧加窗后的信号做快速傅里叶变换(FFT),通常取FFT点数为2的整数次幂,确保计算效率。
得到的FFT结果为复数,取模的平方后除以FFT点数,得到每帧的功率谱,公式为:
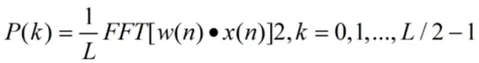
其中,x(n)为第n个采样点的时域信号,L为FFT点数,k为频率点索引。得到频率-功率分布的频谱,横轴为频率(0-Fs/2),纵轴为对应频率的能量强度。
(3)梅尔滤波:
通过一组按“梅尔刻度”分布的三角滤波器,该滤波器特点是低频密集、高频稀疏,模拟人耳感知特性,过滤无关频率成分。
人耳对频率的感知并非线性往,往是对低频敏感、高频迟钝,梅尔频率(Mel)与物理频率(f,单位Hz)的映射关系为:
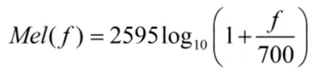
基于此设计梅尔滤波器组。
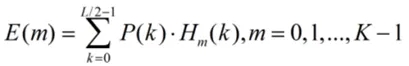
其中,Hm(k)为第m个梅尔滤波器的权重,仅在对应频率区间内非零,呈三角形状。经过以上步骤,就可以尽可能过滤掉与语音识别无关的高频噪声和冗余频率成分,聚焦人耳敏感的核心频段。
线性频率与梅尔频率的映射关系如下图所示:
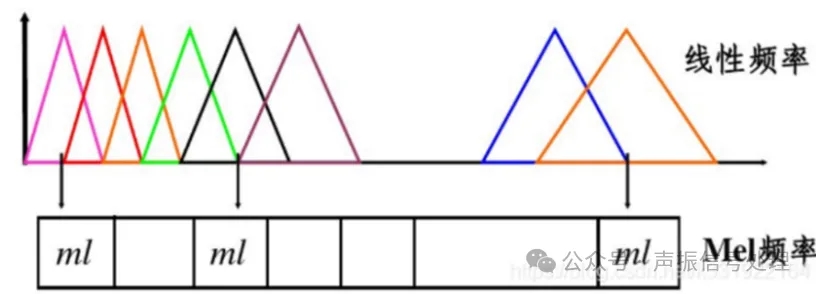
图片来源于网络
(4)对数与倒谱变换:
对滤波后的能量取对数,这一步也是为了贴合人耳响度感知,再通过离散余弦变换(Discrete Cosine Transform,DCT)提取低频倒谱系数,最终得到12-13维核心参数。
人耳对声音响度的感知遵循对数规律,且频谱的包络信息,即对应声纹的音色特征是主要集中在低频倒谱系数中,对每个梅尔滤波器的能量E(m)取自然对数,贴合人耳响度感知,公式为:
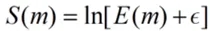
其中ε为极小值(如1e-10),避免能量为0时对数无意义;
(5)离散余弦变换(DCT):
把对数能量S(m)做DCT,提取低维倒谱系数,忽略高频倒谱系数(主要对应频谱细节噪声),以13维为例,公式为:
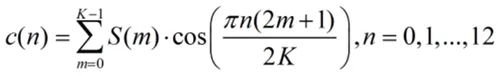
其中n为倒谱系数索引。
接着还需要进行直流分量处理,第0维倒谱系数c(0)对应信号的平均能量,通常会被归一化或移除,避免音量差异带来的干扰。
MFCC聚焦与人耳感知相关的核心差异,能过滤情绪、音量等干扰因素。哪怕模仿者刻意复刻语气,其共鸣腔结构无法复制,导致MFCC参数出现显著偏差,这也是模仿者难以以假乱真的核心原因。
3、动态特征
动态特征反映说话人的后天发声习惯,是区分模仿者与本人的关键补充。
如:语速特征,指单位时间内的发音字数、音节间隔时长。
有人说话急促,有人说话舒缓,这种节奏习惯长期稳定,难以刻意模仿。

此外还有声调起伏,即语调的动态变化,比如疑问句结尾的升调幅度、陈述句的降调斜率,都带有强烈的个人印记。提取时需计算F0轨迹的斜率、峰值数、波动幅度等参数。
动态特征弥补了基础特征的局限性。比如:同卵双胞胎的声带、共鸣腔结构相似,基础特征差异较小,但动态特征(语速、语调习惯)仍有明显区别,可通过这一维度实现精准区分。
四、匹配识别
系统将提取的声纹特征,通常是基础特征、MFCC配合上动态特征的组合向量形式,与数据库中存储的模板进行比对,有两类验证模式。
一类是1:1验证,如手机解锁、支付验证。
主要是判断当前声纹与注册者是否一致,阈值通常设为95%以上相似度;
另一类是1:N识别,如安防监控、寻找失联人员。
这一类主要是在海量声纹库中筛选匹配对象,需平衡速度与准确率。
目前主流技术采用深度学习模型,如CNN、LSTM等,通过大量语音数据训练,让机器对声纹的识别准确率远超人类听觉。

总结:
声纹识别作为生物识别领域的重要分支,凭借声音的唯一性与稳定性,已成为远程身份验证的技术之一。其核心原理是通过捕捉说话人先天生理结构与后天发声习惯共同塑造的独特声纹特征,实现精准身份区分,声纹的个体差异为识别提供了坚实基础,即便模仿者刻意复刻语气,也难以复制发声器官的物理结构与长期形成的发声习惯。
今天声纹识别早已跳出技术圈,渗透到我们的日常,尤其在需要远程身份验证的场景中大放异彩:
在智能设备场景中,手机语音助手、智能音箱、汽车解锁与控制,通过声纹识别区分人员身份,有效避免隐私泄露,企业考勤系统也引入声纹打卡,成功解决远程办公的考勤难题;而在公共安全与特殊场景中,公安系统可通过监控录音的声纹比对锁定犯罪嫌疑人,司法领域中声纹能作为电子证据辅助断案,对于残障人士而言,声纹识别更能替代键盘、触屏,成为便捷的设备操作方式。

Copyright © 2018,All rights reserved 广州辰方互联信息科技有限公司 版权所有 备案号:粤ICP备18085845号
联系电话:020-37681030
销售热线:18520175978(微信同号)
公司地址: 广州市海珠区红卫新村西街29号UP智谷B1栋417室